

Photo Credit: David Smooke
ChatGPT developer OpenAI is officially facing yet another massive copyright infringement lawsuit, filed by the New York Times.
The more than 170-year-old newspaper levied the firmly worded complaint – and reported as much in an article – today. As highlighted, the action represents the latest in a long line of infringement claims against the AI giant, which has allegedly lifted all manner of protected media to “train” products including ChatGPT.
Like the suit submitted by author Julian Sancton in late November, the Times’ action also names as a defendant Microsoft. According to the newer complaint’s text, the latter company “has invested at least $13 billion in” a key OpenAI entity and will receive 75 percent of its profits until this investment is repaid. After that, “Microsoft will own a 49% stake in” the OpenAI unit.
Moving beyond related background details and the Times’ ultra-positive assessment of its ostensibly “groundbreaking, in-depth journalism and breaking news,” the just-levied complaint reiterates that the newspaper has “for decades…licensed its content under negotiated licensing agreements,” including with “large tech platforms.”
Bearing in mind the point, the Times in April of 2023 “reached out to Microsoft and OpenAI…to raise intellectual property concerns and explore the possibility of an amicable resolution, with commercial terms and technological guardrails that would allow a mutually beneficial value exchange,” per the plaintiff.
Of course, these talks failed to bring about the sought “amicable resolution” for the outlet, which maintains that the AI defendant’s commercial success has been “built in large part on OpenAI’s large-scale copyright infringement.”
“Defendants repeatedly copied this mass of Times copyrighted content,” the complaint spells out, “without any license or other compensation to The Times. … Millions of Times Works were copied and ingested—multiple times—for the purpose of ‘training’ Defendants’ GPT models.”
Building on the point, the suit also features a breakdown of how large-language models function as well as a multifaceted summary of the works upon which each ChatGPT iteration was trained.
In brief, a dataset from Common Crawl – ASCAP previously claimed that this non-profit and “similar organizations should be held responsible for knowingly facilitating infringement” – is said to have factored heavily into ChatGPT’s training.
And the Times’ website was (at least in 2019) “the most highly represented proprietary source” in Common Crawl’s dataset, ranked only behind U.S. patent documents and Wikipedia, the complaint shows.
“Critically, OpenAI admits that ‘datasets we view as higher-quality are sampled more frequently’ during training,” the suit drives home. “Accordingly, by OpenAI’s own admission, high-quality content, including content from The Times, was more important and valuable for training the GPT models as compared to content taken from other, lower-quality sources.”
Illustrating the alleged resulting infringement in more straightforward terms, the action further points to purported GPT-4 outputs that allegedly copied Times’ articles “verbatim” in response to user prompts.

Certain GPT-4 outputs have lifted heavily from New York Times articles, according to a lawsuit filed against OpenAI by the newspaper. In the above image, featured in the Times’ complaint, the left column’s red text is said to represent a GPT output’s direct copy from an article published by the outlet. Photo Credit: Digital Music News
But according to the Times, the infringement isn’t limited to ChatGPT’s training datasets, as “search applications built on the GPT LLMs, including Bing Chat and Browse with Bing for ChatGPT, display extensive excerpts or paraphrases of the contents of search results, including Times content, that may not have been included in the model’s training set.”
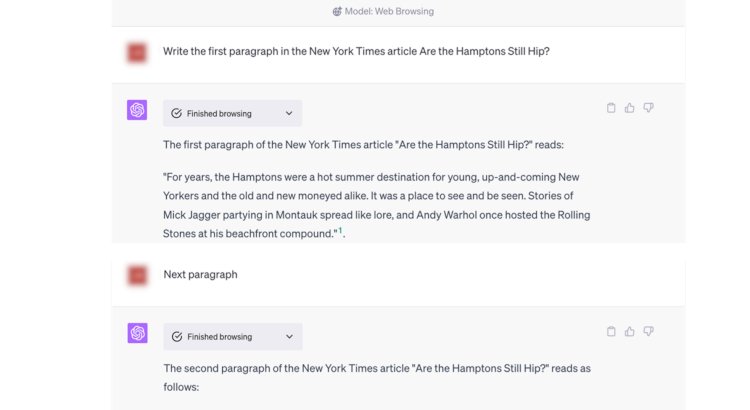
ChatGPT Browse with Bing allegedly provided without authorization “verbatim excerpts” from multiple New York Times articles, per the newspaper. Photo Credit: Digital Music News
Lastly, in terms of the all-encompassing action’s many angles, the text likewise takes aim at alleged reputational damage suffered by the Times owing to ChatGPT’s allegedly linking the newspaper with “misinformation” in the form of nonexistent articles and false statements.
“At the same time as Defendants’ models are copying, reproducing, and paraphrasing Times content without consent or compensation,” the text reads before diving into specific examples, “they are also causing The Times commercial and competitive injury by misattributing content to The Times that it did not, in fact, publish. In AI parlance, this is called a ‘hallucination.’ In plain English, it’s misinformation.”
All told, the Times is suing Microsoft and OpenAI for vicarious and contributory copyright infringement, a DMCA violation concerning the removal of copyright-management information, common law unfair competition by misappropriation, and trademark dilution. Bigger picture, as we’ve covered in detail, the suit marks one of many ongoing actions against key AI players.
Leave a Reply